
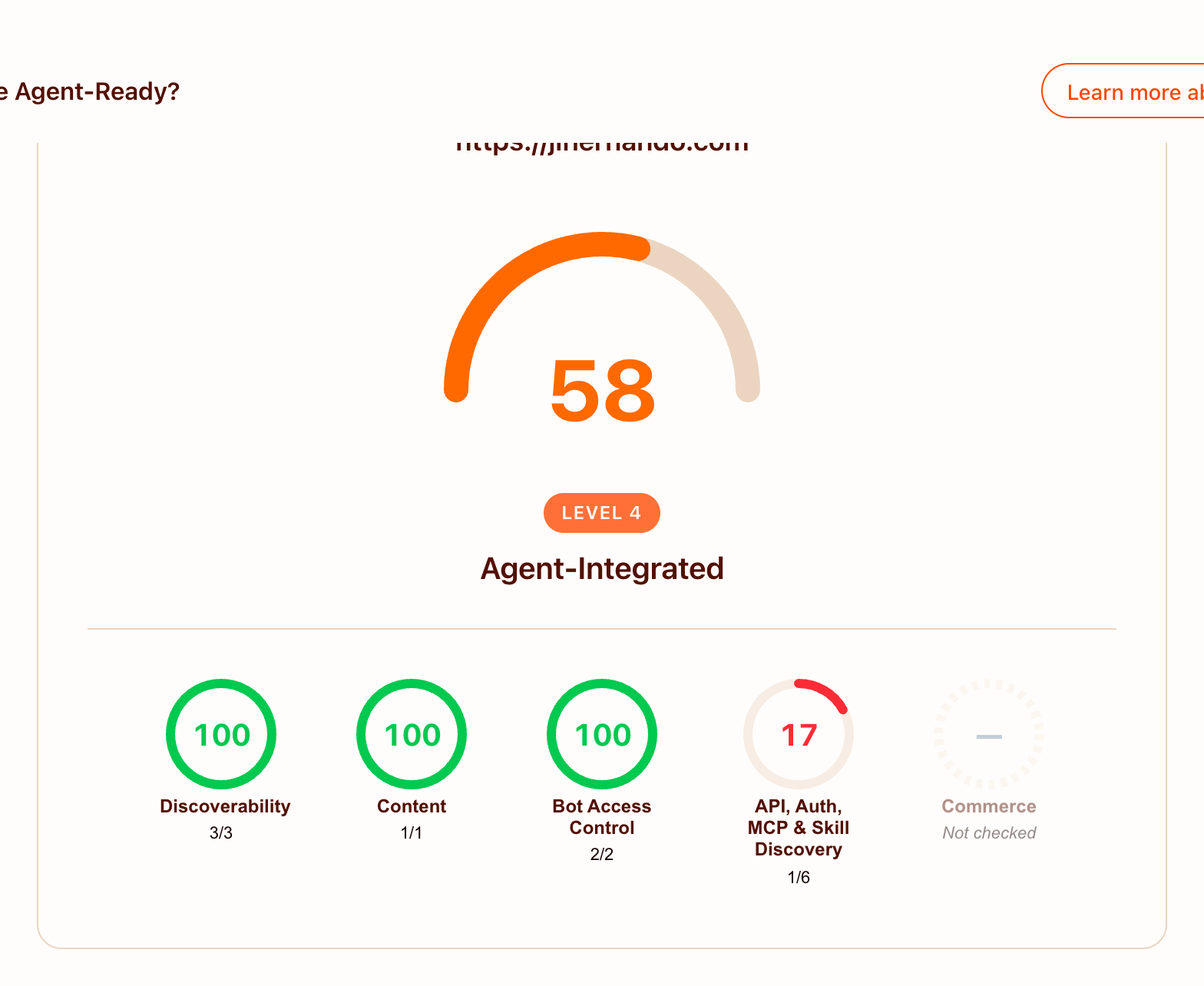
A few days ago I read Suganthan’s post on how to make websites agent-ready and decided to put it through its paces on this site. One session later, isitagentready.com gives jlhernando.com a Level 4 (Agent-Integrated) score, and almost everything that’s still red on my report card is something a personal SEO blog should leave red.
This post is the walkthrough: the tactics I shipped, the small handful that bit me on the way, and the ones I deliberately skipped. I worked together with Claude on it.
Why bother
“Agent-ready” is a useful umbrella term for everything you can ship today to make your site cooperative with AI crawlers, AI search products, and browser-driving agents. Some of it is just good SEO (XML sitemaps, semantic HTML, clean robots.txt). Some of it is new (llms.txt, Markdown content negotiation, Agent Skills indices). And some of it is forward-looking infrastructure (MCP, A2A, WebMCP) that mostly makes sense for SaaS or commerce, not for a personal blog.
The honest pitch for shipping the agent-ready stack on a content site is option value: tiny, inexpensive signals that might improve AI search visibility, citation quality, and crawl efficiency now, and almost certainly will be needed later. None of it guarantees citations today. Anyone who promises otherwise is selling something.
The audit
I started with a flat checklist: every tactic Suganthan mentions, mapped to one of three buckets:
- HIGH: easy to ship, on-brand for an SEO consultant’s site
- MEDIUM: useful but more work
- LOW / SKIP: doesn’t apply (no APIs, no MCP server, not a shop)
The full list of 28 tactics shook out into 4 high-impact items, 3 medium, and ~15 that were N/A for a static content site.
The audit took 20 minutes. The implementation took the rest of the session.
How likely is any of this to affect citations?
The honest answer to “will agent-readiness change my citation rate?” is I don’t know yet, and neither do you. There’s almost no public data on which signals AI search products like Perplexity, ChatGPT, or AI Overviews actually use to choose what they cite. Everyone is guessing, including the people selling courses about it.
So before shipping anything, I scored each tactic on a transparent 0-10 rubric I’ll call the Citation Probability Score (CPS). Five criteria, 0-2 points each:
- Read by today’s bots. 0 = no evidence, 1 = plausible, 2 = confirmed by a vendor or by my own traffic logs
- Used by AI search products. 0 = no, 1 = indirect (likely consumed in training), 2 = direct in retrieval/grounding
- Industry alignment. 0 = single vendor or proposal, 1 = multiple vendors back it, 2 = W3C/RFC/IETF-class standard
- Marginal information. 0 = duplicates HTML or sitemap, 1 = adds context, 2 = net-new entity or structured signal
- Time-to-value. 0 = multi-day build, 1 = hours, 2 = minutes
Summed:
| Tactic | Read | AI search | Alignment | Marginal | Time | CPS |
|---|---|---|---|---|---|---|
llms.txt + llms-full.txt | 1 | 1 | 1 | 1 | 2 | 6 |
Named-bot robots.txt + Content-Signal | 2 | 1 | 1 | 1 | 2 | 7 |
HTTP Link headers + <link> tags | 1 | 0 | 2 | 0 | 2 | 5 |
Blog served as Markdown (negotiation + .md) | 2 | 1 | 2 | 1 | 1 | 7 |
SKILL.md + skills.json | 1 | 0 | 1 | 1 | 1 | 4 |
| EntityMap | 0 | 0 | 0 | 2 | 1 | 3 |
| Public "INSTRUCTIONS FOR AI ASSISTANTS" block Experiment | 2 | 2 | 0 | 1 | 2 | 7 |
| Skipped: on the list but not for a personal SEO blog | ||||||
| MCP server card (for a content site) | 1 | 0 | 1 | 0 | 0 | 2 |
| A2A agent card | 0 | 0 | 1 | 0 | 0 | 1 |
| WebMCP widget | 0 | 0 | 0 | 0 | 0 | 0 |
6 to 8 likely / measurable 3 to 5 plausible / uncertain 0 to 2 long shot
A few observations from staring at this:
- The highest-scoring items are the most “SEO-adjacent.” Named-bot robots, Link headers, and Markdown content negotiation are RFC-era discovery patterns that AI vendors can map onto existing crawl plumbing. That’s not a coincidence.
- The lower-scoring items are the speculative ones.
SKILL.md/skills.json, EntityMap, MCP / A2A: all proposed in the last 18 months, none with public consumption commitments from a major AI vendor. The case for them is option value, not measured ROI. - Time-to-value is consistently high. Almost everything ships in a day or two when generated from existing Eleventy data. That’s what makes the option-value argument coherent: this is cheap insurance, not a quarterly bet.
- There’s no 9 or 10 on this list. If anyone tells you a specific tactic is a guaranteed citation lift today, they are selling something.
I’ll re-score in six months. If anything moves, it’ll most likely be Markdown content negotiation (more vendors confirm reads) and llms.txt (either it gets a standards-body home or it quietly dies).
What I shipped (the core)
1. /llms.txt and /llms-full.txt
Two Markdown files that describe the site for agents:
/llms.txt: a concise index. Title, summary, and link for every blog post and tool. ~70 lines./llms-full.txt: the full text of every post, concatenated. ~1,400 lines. Useful when an agent wants the whole corpus in a single fetch.
Generated at build time by Eleventy templates (llms.njk and llms-full.njk) that iterate over collections.blog. The full version uses a custom rawBody filter that reads each post’s source file, strips the YAML frontmatter with gray-matter, and emits the Markdown body unchanged:
eleventyConfig.addFilter('rawBody', (inputPath) => {
if (!inputPath) return '';
const source = fs.readFileSync(inputPath, 'utf8');
return matter(source).content.trimStart();
});2. Named AI bots + Content-Signal in /robots.txt
The robots.txt now has explicit User-agent blocks for GPTBot, ClaudeBot, PerplexityBot, Google-Extended, CCBot, Applebot-Extended, Meta-ExternalAgent, Bytespider, ChatGPT-User, Claude-User, OAI-SearchBot, Perplexity-User, Claude-SearchBot, anthropic-ai, and cohere-ai. All set to Allow: / with Disallow: /admin/, plus a Content-Signal line declaring usage permissions:
User-agent: GPTBot
Allow: /
Disallow: /admin/
Content-Signal: ai-train=yes, search=yes, ai-input=yesThe Content-Signal extension separates “you can read me” from “you can train on me.” Today it’s mostly aspirational, but the cost of writing it down is one line per bot.
Gotcha: per the robots.txt spec, a specific User-agent group does not inherit rules from User-agent: *. So Disallow: /admin/ has to be repeated under each named bot, or those bots will be allowed to crawl /admin/. I forgot this on the first pass.
3. HTTP Link headers + matching <link> tags
Two ways to advertise the agent-readable resources:
- HTTP
Linkheaders on every response, pointing to the sitemap,llms.txt,llms-full.txt, andskills.json - HTML
<link rel="describedby|sitemap|alternate">tags in every page’s<head>, via a sharedpartials/agent-links.njkpartial included from bothbase.njkandpost.njk
The header values look like this:
Link: <https://jlhernando.com/sitemap.xml>; rel="sitemap"; type="application/xml",
<https://jlhernando.com/llms.txt>; rel="describedby"; type="text/markdown",
<https://jlhernando.com/llms-full.txt>; rel="describedby"; type="text/markdown",
<https://jlhernando.com/.well-known/skills.json>; rel="alternate"; type="application/json"
4. Every blog post served as Markdown
Every post on this blog is now reachable in two formats:
/blog/<slug>/: the rendered HTML page/blog/<slug>.md: the raw Markdown body, frontmatter stripped
A paginated Eleventy template (blog-md.njk) generates the static .md files at build time. A Netlify edge function on /blog/* handles two extra cases:
- If you
GET /blog/<slug>/withAccept: text/markdown, the edge function serves the.mdcontent inline withContent-Type: text/markdown,Vary: Accept,Content-Location: /blog/<slug>.md, and aLink: rel="canonical"pointing back to the HTML page. - If you
GET /blog/<slug>.mddirectly, the sameLink: rel="canonical"is attached so search engines treat the two URLs as alternate representations of the same resource, not duplicate content.
The visible “View as Markdown” link in every post header uses rel="alternate", so search engines understand it the same way they understand language alternates or AMP variants.
5. /SKILL.md and /.well-known/skills.json
Two complementary files describing what jlhernando.com offers an agent:
SKILL.md: instructions in the Anthropic-style format. YAML frontmatter (name,version,description,inputs) followed by Markdown explaining when to use the skill, how to fetch posts (Markdown is preferred, with Accept-header negotiation or direct.mdsuffix both working), and what not to do (don’t fabricate URLs, don’t paraphrase code without linking the post).skills.json: the machine-readable version, listing the same skill with input parameters, available resources, and content-negotiation hints.
Both files are also reachable at the alias paths scanners look for: /.well-known/agent-skills/index.json (v0.2.0 spec) and /.well-known/skills/index.json (legacy). Aliased via 200-status redirects in _site/_redirects.
6. Server-side Plausible tracking for agent-readable resources
Because none of llms.txt, llms-full.txt, SKILL.md, skills.json, or the raw .md blog files serve any HTML, the client-side Plausible snippet can’t see them. So I added two edge functions:
blog-markdown-negotiationfires a “Markdown Read” event on every.mdfetch (direct or Accept-negotiated)agent-resources-trackerfires an “Agent Resource Read” event for the four static agent-discovery files
Both share a lib/classify-ua.ts module that returns { agent_class, bot_family, bot_kind, bot_name, is_bot } for any User-Agent string. Plausible custom properties carry those tags, so the dashboard breaks down agent reads by openai vs anthropic, training vs ai-search, scripted vs human, and so on.
The actual events POST is wrapped in context.waitUntil(), so the response ships before the analytics fetch resolves and the user-visible request never blocks on Plausible.
The gotchas
Three of these cost me time:
Netlify silently drops broad [[headers]] blocks
I spent an embarrassing amount of time debugging why my catch-all Link header wasn’t appearing. I tried every TOML value syntax: literal string, triple-quoted, array of strings. The block [[headers]] for = "/*" was being silently ignored.
The exact same syntax worked on specific paths ([[headers]] for = "/blog/*.md"), so the issue is scoped to the wildcard. I never figured out the root cause. Moving the header to _site/_headers (a file Netlify reads directly from the publish directory) made it apply immediately.
_site/_redirects shadows netlify.toml redirects
When you have both a _redirects file in the publish directory and [[redirects]] blocks in netlify.toml, Netlify processes _redirects first. If a path matches a _redirects entry, the TOML version is never tried.
I added the /.well-known/agent-skills/index.json and /.well-known/skills/index.json aliases in TOML first. They had no effect. Moving them to _site/_redirects made them apply.
Scanners check the homepage, not just blog posts
My first edge function did Markdown content negotiation only on /blog/*. The scanner tested GET / with Accept: text/markdown and got back text/html, so it marked Markdown negotiation as a fail.
The fix was a second edge function on path / that serves /llms.txt content when Markdown is requested. llms.txt IS effectively the homepage-for-agents, so this is conceptually clean. It also fires a “Homepage Markdown Read” Plausible event with the same bot props.
What I deliberately skipped
The scanner shows seven failing checks I’m not going to fix:
- API Catalog, OpenAPI Spec, OAuth Discovery, OAuth Protected Resource: I don’t run a public API or authenticated endpoints. None of these apply.
- MCP Server Card, A2A Agent Card: I don’t host an MCP server, and my site isn’t an agent endpoint. Advertising either would be lying.
- WebMCP widget: I could ship a JavaScript library that exposes the site to MCP clients via a local WebSocket bridge. But the only “skill” I’d plausibly expose is “search the blog,” which is mostly redundant with
/llms.txt. Not worth the JS bundle. - Web Bot Auth via CDN: would require Cloudflare or a similar bot-management platform. Netlify-only deploy.
And the five commerce checks (x402, MPP, UCP, ACP, AP2) are all about agent-driven commerce. Not a shop.
The point of the audit phase wasn’t to score 100/100. It was to identify which signals are real for this kind of site. The remaining red marks are honest signals to a scanner that I’m a content site, not a SaaS or marketplace.
Beyond Suganthan’s list: EntityMap
A few days after wrapping the audit I came across EntityMap.org, an open standard from Waikay/InLinks that pitches a different angle than llms.txt. It’s not in Suganthan’s checklist and isitagentready.com doesn’t grade for it. I shipped it anyway.
The pitch in one line: where sitemap.xml declares what pages exist and llms.txt declares here is the content, in order, entitymap.json declares here are the entities this site knows about, and the evidence chunks behind each one. Entity-first instead of page-first.
The v1.0 spec is small: a root object (version, schema, publisher, generated, entities), an entity object (entityId, @type, name, description, hasChunks), and a chunk object (chunkId, text ≤ 600 chars, sourceUrl, pageTitle, publisher). The chunk’s publisher value must match the root exactly, which is the attribution mechanism that survives extraction into vector databases. Discovery follows the same pattern as the rest of the stack: an EntityMap: line in robots.txt, a <link rel="entitymap"> in every page head, an HTTP Link header, and a visible footer link to the HTML companion.
I generated it from existing Eleventy data. A curated entity catalog in _data/entitymap.js declares the 9 entities I care about: me, Adevinta, Technical SEO, Google Apps Script, Google Search Console, the URL Inspection API, the GSC Index Coverage Extractor, the Bulk Index Inspect tool, and “agent-ready website” itself. Each entity has a sourceSlugs array mapping to blog post slugs. A custom Nunjucks filter joins the catalog with collections.blog at build time and emits a spec-compliant payload:
eleventyConfig.addFilter('buildEntityMap', (catalog, posts, publisher, generated) => {
const postBySlug = {};
posts.forEach((p) => { if (p.fileSlug) postBySlug[p.fileSlug] = p; });
const entities = catalog.map((entry) => {
const chunks = [];
(entry.sourceSlugs || []).forEach((slug, i) => {
const post = postBySlug[slug];
if (!post || !post.data.summary) return;
chunks.push({
chunkId: `${entry.entityId}_c${String(i + 1).padStart(2, '0')}`,
text: post.data.summary,
sourceUrl: `https://jlhernando.com${post.url}`,
pageTitle: post.data.title,
publisher: publisher.name,
});
});
return { entityId: entry.entityId, '@type': entry.type, name: entry.name,
description: entry.description, hasChunks: chunks, /* optional fields */ };
});
return { version: '1.0', schema: 'https://entitymap.org/spec/v1.0',
publisher, generated, entities };
});Cost: roughly half a day, mostly editorial work on the catalog. Output: 9 entities, 21 chunks at https://jlhernando.com/entitymap.json, with a human-readable view at https://jlhernando.com/entitymap.html.
One implementation gotcha worth flagging: my Apps Script entity’s source list pointed at three blog posts and only two chunks came through. The third (apps-script-formulas-seo) has eleventyExcludeFromCollections: true in its frontmatter, so it’s not in collections.blog and the filter silently skipped it. If you build something similar, log unresolved slugs during the join.
The honest caveats are big. Adoption is one reference implementation (Waikay’s own). EntityMap isn’t part of the NIST AI Agent Standards Initiative, not in the MCP/A2A ecosystem, and no major AI vendor has committed to read it. The standard’s backer is a commercial SEO entity-linking product, which is also worth knowing when you weigh whether to invest.
So why ship it? Same logic as the rest of the stack: option value. A spec-compliant entitymap.json is a few hundred lines of JSON regenerated from data I already publish. If EntityMap goes nowhere, I’ve lost half a day. If it gets traction, the site is already there.
On the CPS rubric above, EntityMap scores a 3, all of it on the marginal-information axis. That’s the honest profile of a forward-looking option-value bet: low alignment, no confirmed reads, but it carries genuinely new structured signal that nothing else in the stack provides. Worth shipping for me, not necessarily worth shipping for you.
Score progression
Three rounds of scanning to chase down the last fails:
| Round | Level | What I’d just shipped |
|---|---|---|
| Baseline | unknown | (no agent-readiness signals before this session) |
| v1 | 2 (Bot-Aware) | llms.txt, AI-bot robots rules, blog .md content negotiation |
| v2 | 3 (Agent-Readable) | Homepage Markdown negotiation |
| v3 | 4 (Agent-Integrated) | Agent Skills aliased at scanner-expected paths |
I could have gotten to Level 4 in fewer rounds by reading the scanner’s path expectations first instead of inferring them from the spec. Lesson: when you have a checker that gives you structured feedback, fire it early.
What’s left
The medium-priority items from the original audit are still pending:
- A Lighthouse pass focused on tap-target sizing and any ghost overlays on the hero
- A
navigator.modelContextdemo exposing asearch_blogtool, which would make a nice follow-up post once the API is stable in Chrome - A spot-check on whether the new Plausible events show real bot vs human ratios on the
.mdURLs (the prediction is bots dominate, but I want numbers)
Everything in this post is live on jlhernando.com, and every file mentioned (templates, edge functions, the shared classifier) is in the repo behind this site. If you want to run the scanner against your own site: https://isitagentready.com.
Get notified when I publish new tools, scripts, and articles.
No spam. Unsubscribe anytime.